Predictive Lead Scoring:
A Machine Learning based approach. ©*

What is Lead Scoring?
In sales and marketing, lead scoring is referred to a process which a lead is assigned a numerical value called a score which shows how qualified or ready a
lead is to go to the next stage in the sales and marketing funnel. Depending on the business objective, a lead could be scored towards a specific marketing goal such
as filling out a form, taking a specific action, or being nudged through the sales funnel, aka becoming an SQL (Sales Qualified Lead), or simply towards the business
end goal which is customer acquisition. In other words, it’s very important that the lead scoring process is built toward a solid defined end goal, and that end goal
is what defines the mechanism of the scoring.
Throughout my experience, one key challenge that many teams and individuals face is identifying the end goal for their lead scoring project, which in many cases end
up accepting a vague definition of it and instead, spending more time on what the score of a qualified lead should be. In fact, when it’s not clearly defined what the
score determines, it’s naïve to discuss what the values behind the lead scoring should be.
When the end goal for the lead scoring process is determined, it’s time to look at the leads that have already passed through that end goal and analyze what they had in
common priorly. For instance, if the end goal is acquisition, the leads that have converted into clients should be selected and their attributes need to be analyzed to
identify their similarities. This would help understand what attributes with what values should be scored. In analyzing the leads, several attributes and data points
including demographic information, online and offline behavioral factors, Email and campaign engagement, etc. can be selected. The selection of the attributes mostly
goes back to the teams and business’s decisions and is also limited to the availability of data.
So far, we defined the high-level business framework around lead scoring but what’s left is one very important complex part of building the actual process and making it
a reality: How to analyze data and calculate the score.
Calculating the lead score:
For this step, there are several ways used by marketing and data professionals including conducting trial and error on business selected attributes or conducting univariate analysis in Excel, which have their own advantages and disadvantages. But in this article, I'm presenting a fully data-driven lead scoring methodology using predictive analytics and machine learning (ML) that minimizes human judgment error, maximizes the use of data, and lets the ML algorithms accurately extract the complex patterns from the big data to calculate the final score.
Predictive Lead Scoring using Machine Learning:
In predictive lead scoring, machine learning algorithms analyze big amount of lead records and data points, extract hidden patterns that are too complicated and
sometimes impossible to extract using basic ways e.g., spreadsheets, and identify or predict which leads are more likely to convert.
Building and deploying a predictive lead scoring model in a company is a complex project which has many steps including meeting with relevant stakeholders, gathering
requirements, mapping-out the current and desired processes involving people and technologies, building proposals for the teams, getting buy-in from managers and
leaders, identifying data sources, checking technology availability and gaps, building the model, deploying the model with the right tools and technologies, etc.
It’s highly important to note that when it comes to running a successful analytics initiative in a company like lead scoring, the success vastly depends on a variety
of non-model related factors such as change management and new process implementation.
But in this part, I’m only going through the main high-level steps in building the actual analytical model.
1. Data understanding and collection:
When it became known on what end you’re building the model towards (e.g., conversion), it’s time to explore what lead data you have in your databases. For this, you could investigate the company’s internal databases (e.g., SQL-based), cloud storage (e.g., Google Big Query), the Marketing Technologies (MarTech) backend, and flat files like Excel spreadsheets. It’s also important to talk to key data people since they can direct you to the right resources. The main idea here is to identify What data of leads is captured Where and How you can access it.
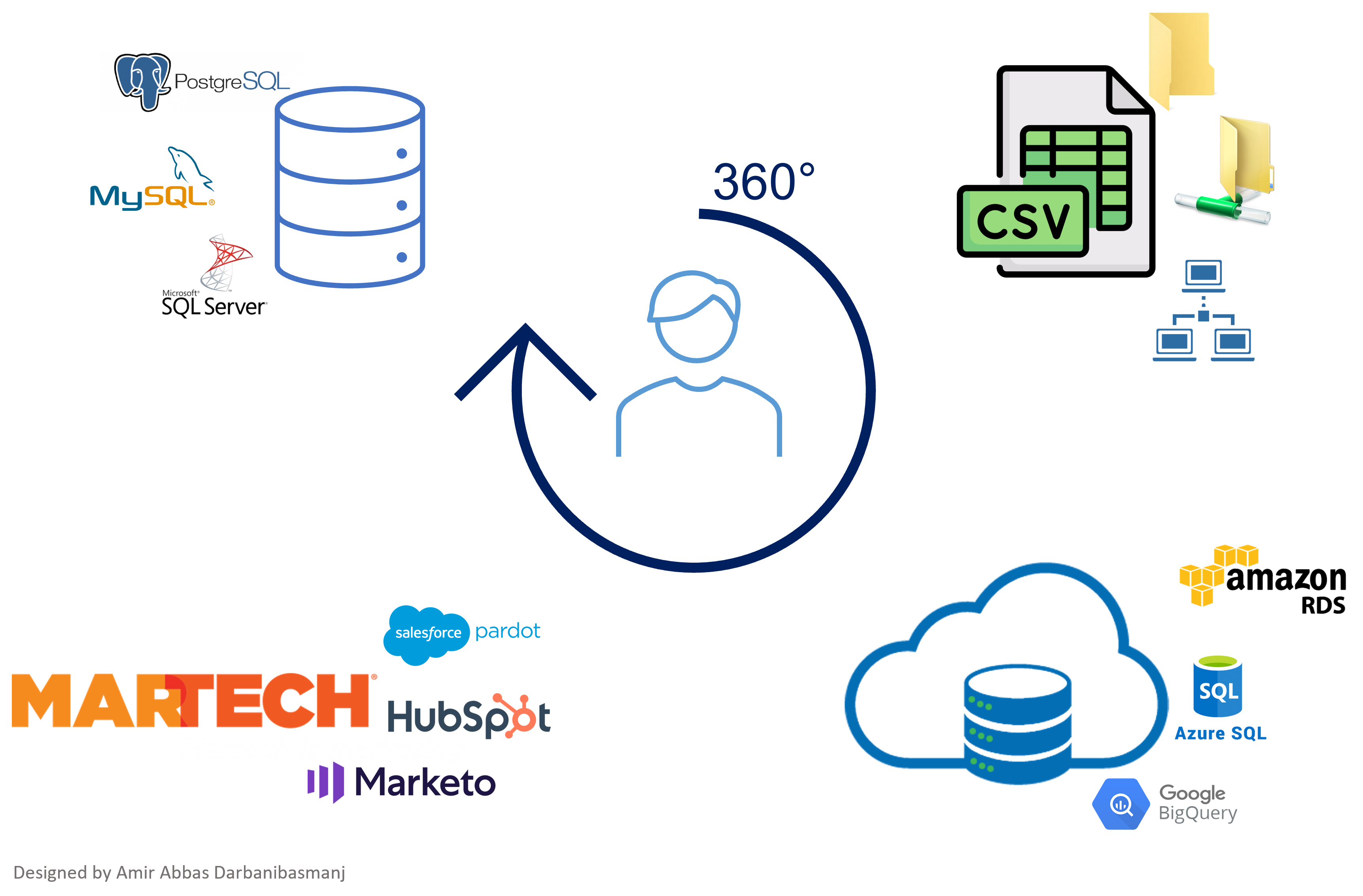
Figure 1: Example of Lead data sources
2. Data cleaning and preparation
After exploring the databases and figuring out what data points are available to be used in your lead scoring model, it’s time to create the master data input file for
your model. This file will be used as your model input so that the ML algorithm can extract and learn the patterns from it. With this learning, your ML model will be
able to calculate the score of a lead and predict the conversion likelihood in the future. More specifically, this data file should contain all the leads and their
corresponding attributes within the selected study time frame, and one last column that shows if the lead was converted in the selected time frame or not. For instance,
if the selected time frame is the year 2021, all leads from 2021 and their attributes like their age, education, region, number of webpage visits, number of forms filled
out, time spent on the website, number of campaign Emails opens, etc., and a column that shows if they converted in 2021 or not should be prepared for this study. It’s
important to note that the features and attributes can be engineered in many ways. it’s in the hand of the expert to know how efficiently engineer the factors to
achieve the best model outcome. For example, some experts use the RFM framework
(Recency, Frequency, and Monetary) to conduct feature engineering where applicable.
Here's an example of the data file:
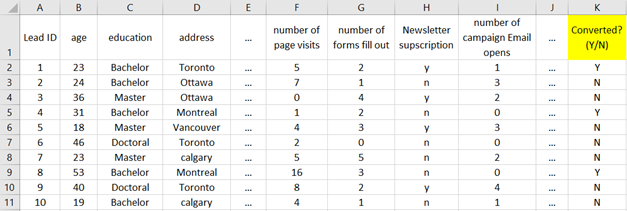
Figure 2: Example of a lead scoring data input file for training machine learning model
3. Building the Machine Learning model
When the master data input file is created, it’s time to train the machine learning model. Using this historical data, ML algorithms learn the patterns and will
be able to make predictions on unseen lead records in the future. As this is a predictive task using labeled dataset (there’s one column at the end of the data file that represents the
dependant variable – “Converted?(Y/N)”), we need to build a supervised machine learning model
(Supervised and Unsupervised Machine Learning).
For building a supervised ML model, there are many algorithms to choose from; here is the list of some of
the well-known ones:
- Decision Trees
- Nearest Neighbors
- Random Forest
- Support Vector Machines (SVM)
- Naive Bayes
- Logistic regression
- Linear regression
- ...
Choosing the right algorithm depends on many factors including the nature and type of data, computational time availability, and what the desired business objectives
and end goal look like. For instance, there are some algorithms and models that work best with your data and give you high prediction accuracy but are hard to extract
rules and patterns from (aka black box models), so if your team wants to interpret the model and e.g., extract rules and patterns from it, then those algorithms won’t
be selected for this task, and instead, a good enough (acceptable accuracy) algorithm that has higher transparency will be chosen at the end. Or if the team is more
interested in having a probabilistic outcome (e.g., knowing with what probability a lead will convert), they may end up selecting the algorithms that can generate such
an outcome.
Of all the mentioned algorithms, Logistic Regression (see Figure 3) is one of the widely used algorithms in different domains.
Some of its successful business use cases are Credit Risk Assessment, Churn Prediction, and of course Lead Scoring. Computational efficiency, accuracy, model
transparency & rule extraction, and ease of understanding & interpretation are some of the advantages that have made Logistic Regression the choice of many experts in
building ML models.
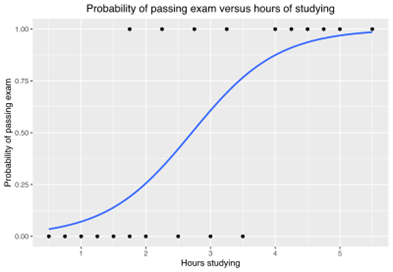
Figure 3: Example graph of a logistic regression curve fitted to data (Source: https://en.wikipedia.org/wiki/Logistic_regression)
Now that we know what supervised machine learning is and what algorithms can be used to build a model, it’s time to choose what tool you want to build the model or write the code with. For this part, there are several choices of software and programming languages to pick from. If you’re into programming, either R or Python could be used to train your model. For Python, there’s a comprehensive dedicated machine learning library called scikit-learn that features a wide variety of ML algorithms alongside many other helpful functions to perform all sorts of data cleaning, preparation, etc.
4. Deploying the Lead Scoring model
After building and interpreting the ML model, it’s time to deploy it into your planned lead qualification journey. Based on the technology availability and human expertise
within a company, such deployment could be highly manual, highly automated, or somewhere in between. For instance, if there’s no opportunity for automation, the expert
should manually extract the list of leads in a spreadsheet, manually run the model on it, and report the results in a flat file format to the user. But if there’s a
chance to automate the process, the model can be deployed within the current data pipelines so the lead data can be moved and loaded into the ML model automatically,
then the model performs prediction task, and the outcome will be moved and ingested into a final database stage to be used by different end users such as sales.
Most of the time, it’s neither of the two scenarios. Companies always have some technologies and expertise available so it’s important to customize the model deployment
based on their resources. For example, if they use marketing automation tools such as Hubspot or Marketo, they can see if these tools offer lead scoring modules. If
they do, instead of trying to deploy the actual model, they can use the insights and rules extracted from it to build the lead scoring module within the platforms.
Overall, figuring out the best deployment plan depends vastly on the technology and expertise available within the company.
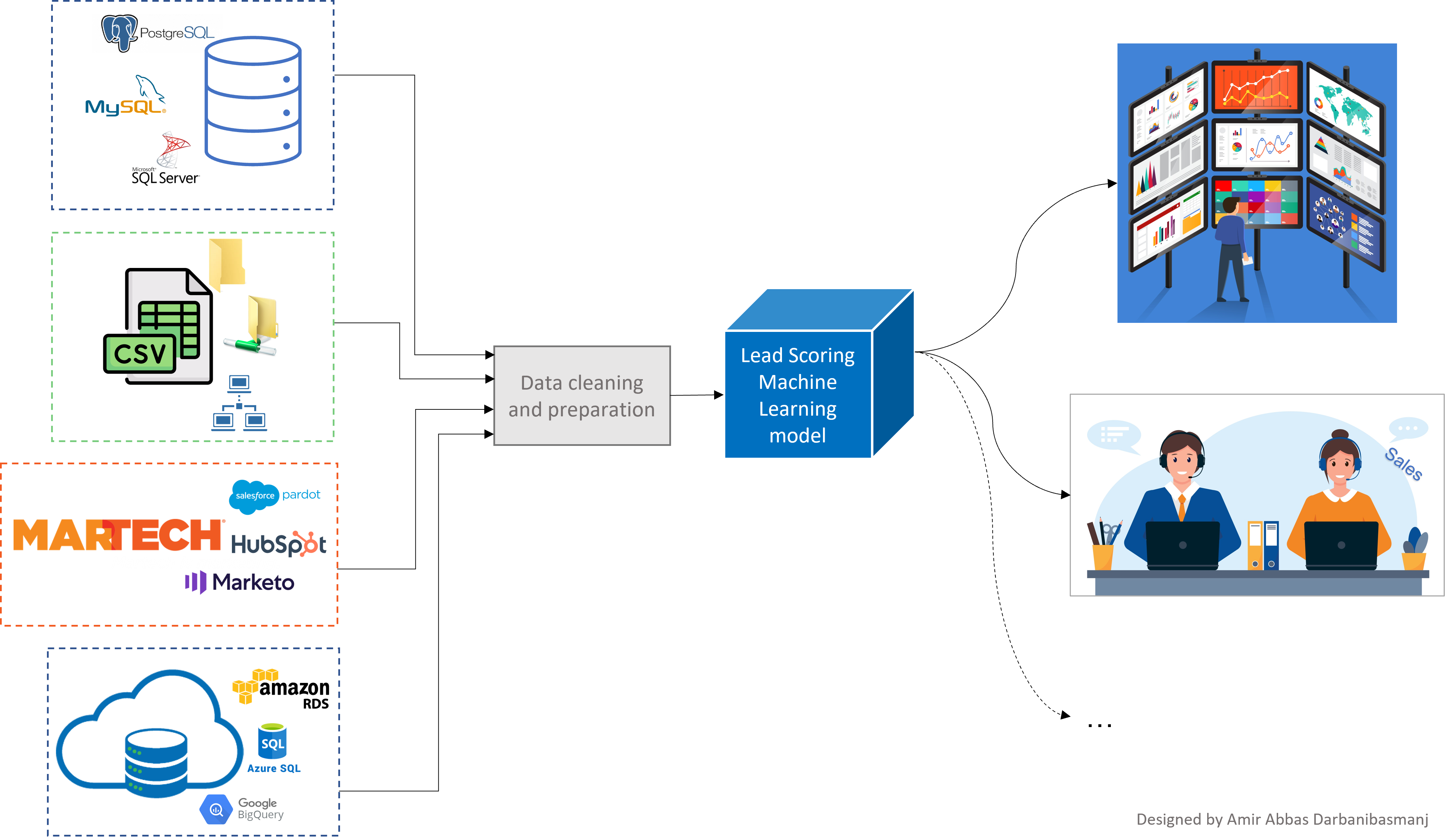
Figure 4: Deploying Lead Scoring Machine Learning model
In this article, I went through what lead scoring is and how you can build a predictive lead scoring model using machine learning. A machine learning-based lead scoring potentially minimizes human judgment error, maximizes the use of data, and accurately extracts complex patterns from the big data to calculate the score.
* This content is subject to copyright and is owned by the author.